剛看到 Embedding 這個名詞一直無法跟向量化聯想在一起,直到看了台大教授陳縕儂的影片才瞭解其中含意,有興趣的朋友可自行看影片學習,這裡簡單說一下概念
Embedding 就是將內容轉成向量數據的一種表現方式,演算法會看有多少維度,依據每個 Token 與一定大小的上下文計算後再去跟 LLM 計算得到向量值,最後將向量數據塞回每個維度中,由於原本向量值是矩陣資料很浪費空間,上面的做法像是把矩陣資料塞進一個維度內,所以才會稱為 Embedding
這些 Embedding 數據有甚麼作用?其實這是向量資料庫用來做近似查詢的依據,也是 RAG 儲存資料跟檢索資料會用到的向量資訊,查詢時會把每個維度的向量利用餘弦相似度或是歐式距離法算出向量間的距離,求出結果最大的前 N 筆數據,最後在將這些資料傳給 AI 幫我們整合內容
接下來就看看 Embedding Model 的 UML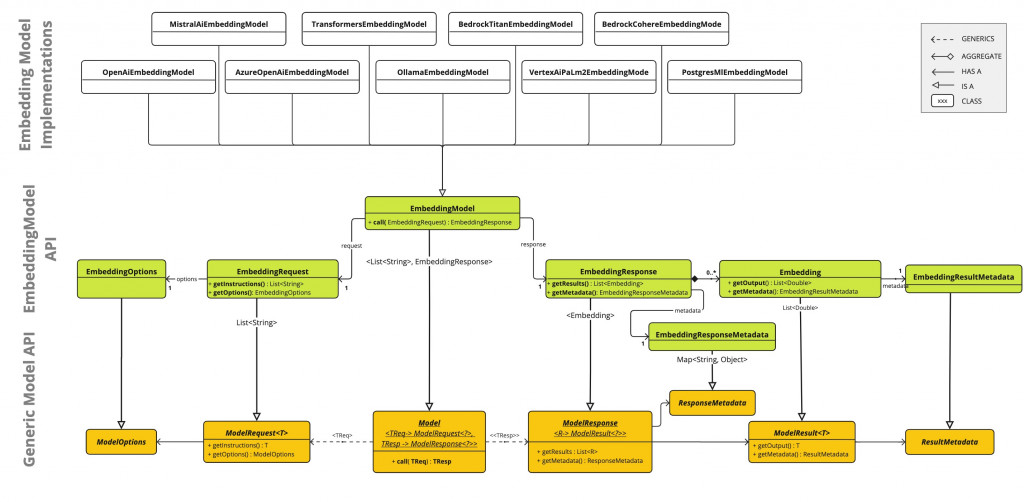
可以看出 Class 結構與前面的 ChatModel 差不多,只差在最後的結果是一堆 Embedding,我們來看看昨天存入向量數據庫的內容,下圖的 embedding 正是每個維度的向量值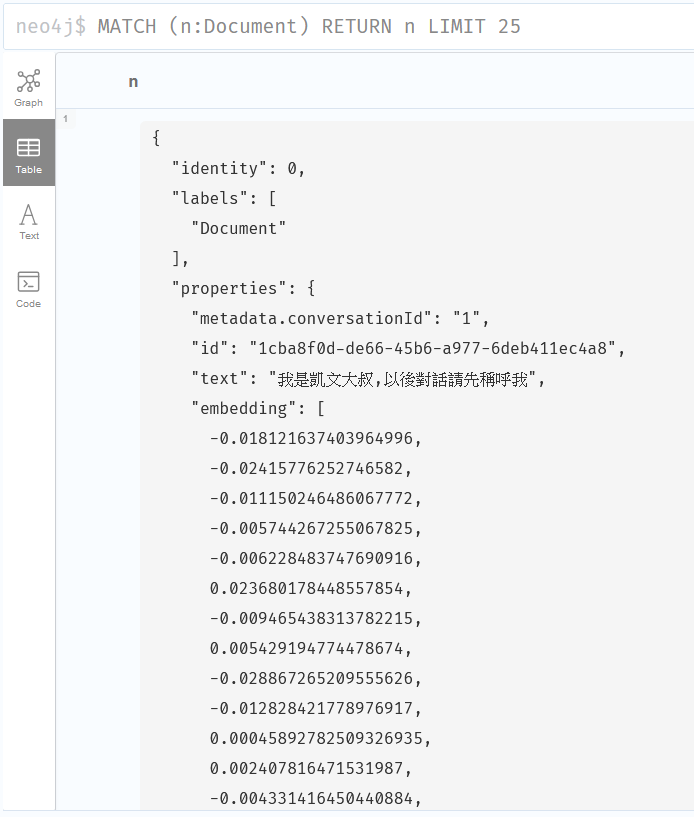
下面我們來寫個簡單的程式,測試一下如何將一段內容轉成 embedding
@RestController
@RequiredArgsConstructor
public class EmbeddingController {
private final EmbeddingModel embeddingModel;
@GetMapping("/embedding")
public List<Double> embed(String message) {
return embeddingModel.embed(message);
}
}
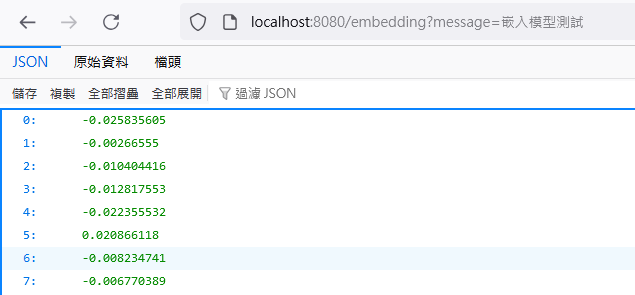
至於 embedding 會有幾個呢?這取決於 Embedding Model 維度的大小,Open AI 預設的Embedding Model 是 text-embedding-ada-002,它的維度是 1536,所以我們的結果也會有 1536 筆,可以用 embeddingModel.dimensions() 方法取得維度
實際上程式碼也是給一段文字取得 embeddings 後在看有多少 size
另外要注意的是向量資料庫儲存資料時除了內容跟 embeddings 外,metadata 也頗為重要,若沒將參考資訊放在 metadata 中,AI 最後只能彙總資料後回答你產生的內容
拿昨天的程式為例最後寫進向量資料庫的內容是下面程式,也就是說我們寫入向量資料庫前將訊息跟 metadata (Map 格式) 合成 Document,這樣向量資料庫就能包含特定資訊
this.getChatMemoryStore().write(toDocuments(assistantMessages, this.doGetConversationId(context)));
private List<Document> toDocuments(List<Message> messages, String conversationId) {
List<Document> docs = messages.stream()
.filter(m -> m.getMessageType() == MessageType.USER || m.getMessageType() == MessageType.ASSISTANT)
.map(message -> {
var metadata = new HashMap<>(message.getMetadata() != null ? message.getMetadata() : new HashMap<>());
metadata.put(DOCUMENT_METADATA_CONVERSATION_ID, conversationId);
metadata.put(DOCUMENT_METADATA_MESSAGE_TYPE, message.getMessageType().name());
var doc = new Document(message.getContent(), metadata);
return doc;
})
.toList();
return docs;
}
思考一下向量資料庫還能加入甚麼內容
今天學到了甚麼?
程式碼下載: https://github.com/kevintsai1202/SpringBoot-AI-Day23.git
凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列


 iThome鐵人賽
iThome鐵人賽